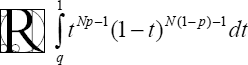The
honor of mathematics requires us to come up with a mathematical theory of evolution and either prove Darwin was wrong or right." Gregory Chaitin
Quote
New Active Information related papers at BIO-Complexity from Evo Info Lab Senior Researchers
Active information is required for successful searches, including evolutionary programming. Three papers at BIO-Complexity explore application and generalization of this required element of evolutionary search. The papers are (1) "Active Information Requirements for Fixation on the Wright-Fisher Model of Population Genetics" by Daniel Andrés Díaz Pachón and Robert J. Marks, (2) "Generalized Active Information: Extensions to Unbounded Domains" also by Daniel Andrés Díaz-Pachón and Robert J. Marks and (3) "Measuring Active Information in Biological Systems" by Jonathan Laine Bartlett. See HERE for links to these papers.
"Using statistical methods to model the fine-tuning of molecular machines and systems"
The Journal of Theoretical Biology published a paper by Steinar Thorvaldsen, a professor of information science at the University of Tromsø in Norway, and Ola Hössjer a professor of mathematical statistics at Stockholm University. The paper notes that fine-tuning is widely discussed in physics, but needs to be considered more in the context of biology. For more information, look HERE.
"Mode hunting through active information"
A new paper by Daniel Andrés Díaz-Pachón, Juan Pablo Sáenz, J. Sunil Rao, and Jean-Eudes Dazard... Abstract. We propose a new method to find modes based on active information. We develop an algorithm called active information mode hunting (AIMH) that, when applied to the whole space, will say whether there are any modes present and where they are. We show AIMH is consistent and, given that information increases where probability decreases, it helps to overcome issues with the curse of dimensionality. The AIMH also reduces the dimensionality with no resource to principal components. We illustrate the method in three ways: with a theoretical example (showing how it performs better than other mode hunting strategies), a real dataset business application, and a simulation. [Link]
"Observation of Unbounded Novelty in Evolutionary
Algorithms is UnknOwable!"
A thought provokoing paper by Eric Holloway and Robert J. Marks... Abstract. Open ended evolution seeks computational structures whereby creation of unbounded diversity and novelty are possible. However, research has run into a problem known as the “novelty plateau” where further creation of novelty is not observed. Using standard algorithmic information theory and Chaitin’s Incompleteness Theorem, we prove no algorithm can detect unlimited novelty. Therefore observation of unbounded novelty in computer evolutionary programs is nonalgorithmic and, in this sense, unknowable. [Link]
Evolutionary Informatics
 Evolutionary informatics weds the natural, engineering, and mathematical sciences. Evolutionary informatics studies how evolving systems incorporate, transform, and export information. The Evolutionary Informatics Laboratory explores the conceptual foundations, mathematical development, and empirical application of evolutionary informatics. The principal theme of the labs research is teasing apart the respective roles of internally generated and externally applied information in the performance of evolutionary systems and capabilities of humans that exceed computation.
Evolutionary informatics weds the natural, engineering, and mathematical sciences. Evolutionary informatics studies how evolving systems incorporate, transform, and export information. The Evolutionary Informatics Laboratory explores the conceptual foundations, mathematical development, and empirical application of evolutionary informatics. The principal theme of the labs research is teasing apart the respective roles of internally generated and externally applied information in the performance of evolutionary systems and capabilities of humans that exceed computation.
DONATE
 Donate?
Donate?
We need your help.
Donations support our ongoing research into Evolutionary Informatics.
We are a federally registered non profit organizations so your donation may be deductible.
Click HERE.
Information & Design
 Intelligent design is the study of patterns in nature best explained
as the product of intelligence. So defined, intelligent design seems
unproblematic. Archeology, forensics, and the search for
extraterrestrial intelligence (SETI) all fall under this definition.
In each of these cases, however, the intelligences in question could
be the result of an evolutionary process. But what if patterns best
explained as the product of intelligence exist in biological systems?
In that case, the intelligence in question would be an unevolved
intelligence. For most persons, such an intelligence has religious
connotations, suggesting that it as well as its activities cannot
properly belong to science. Simply put, intelligent design, when
applied to biology, seems to invoke ‘spooky’ forms of causation that
have no place in science. Evolutionary informatics eliminates this
difficulty associated with intelligent design. By looking to information theory,
a well-established branch of the engineering and mathematical
sciences, evolutionary informatics shows that patterns we ordinarily
ascribe to intelligence, when arising from an evolutionary process,
must be referred to sources of information external to that process.
Such sources of information may then themselves be the result of
other, deeper evolutionary processes. But what enables these
evolutionary processes in turn to produce such sources of
information? Evolutionary informatics demonstrates a regress of
information sources. At no place along the way need there be a
violation of ordinary physical causality. And yet, the regress
implies a fundamental incompleteness in physical causality's ability
to produce the required information. Evolutionary informatics, while
falling squarely within the information sciences, thus points to the
need for an ultimate information source qua intelligent designer.
Intelligent design is the study of patterns in nature best explained
as the product of intelligence. So defined, intelligent design seems
unproblematic. Archeology, forensics, and the search for
extraterrestrial intelligence (SETI) all fall under this definition.
In each of these cases, however, the intelligences in question could
be the result of an evolutionary process. But what if patterns best
explained as the product of intelligence exist in biological systems?
In that case, the intelligence in question would be an unevolved
intelligence. For most persons, such an intelligence has religious
connotations, suggesting that it as well as its activities cannot
properly belong to science. Simply put, intelligent design, when
applied to biology, seems to invoke ‘spooky’ forms of causation that
have no place in science. Evolutionary informatics eliminates this
difficulty associated with intelligent design. By looking to information theory,
a well-established branch of the engineering and mathematical
sciences, evolutionary informatics shows that patterns we ordinarily
ascribe to intelligence, when arising from an evolutionary process,
must be referred to sources of information external to that process.
Such sources of information may then themselves be the result of
other, deeper evolutionary processes. But what enables these
evolutionary processes in turn to produce such sources of
information? Evolutionary informatics demonstrates a regress of
information sources. At no place along the way need there be a
violation of ordinary physical causality. And yet, the regress
implies a fundamental incompleteness in physical causality's ability
to produce the required information. Evolutionary informatics, while
falling squarely within the information sciences, thus points to the
need for an ultimate information source qua intelligent designer.
Research & Resources
Weasel Ware
 A web-based simulation of Dawkins' Weasel. Do the mere presence of replication, mutation and selection guarantee success in a search?
If not, what fraction of all possible fitness functions lead to success? How likely are we to stumble across a successful fitness function if we initialize one at random?
The free simultation lab allows users to answer these questions and more. Simply set up your experiment, choose (or optionally design) your fitness function and record your results.
A web-based simulation of Dawkins' Weasel. Do the mere presence of replication, mutation and selection guarantee success in a search?
If not, what fraction of all possible fitness functions lead to success? How likely are we to stumble across a successful fitness function if we initialize one at random?
The free simultation lab allows users to answer these questions and more. Simply set up your experiment, choose (or optionally design) your fitness function and record your results.
Minivida
 Minivida is a simplified, online simulation of Lenski et. al.'s Avida. It allows the evolution and visualization of NAND-logic programs. With it, you can learn how the choice of rewarded tasks and instructions affects the ability of locating EQU operations. Does the process of mutation and selection alone allow the evolution of complex operations or is the presence of stair step information necessary in order to guide the process? Run the simulation and see what role user-supplied information plays in the discovery of complex features.
Minivida is a simplified, online simulation of Lenski et. al.'s Avida. It allows the evolution and visualization of NAND-logic programs. With it, you can learn how the choice of rewarded tasks and instructions affects the ability of locating EQU operations. Does the process of mutation and selection alone allow the evolution of complex operations or is the presence of stair step information necessary in order to guide the process? Run the simulation and see what role user-supplied information plays in the discovery of complex features.
Ev Ware
 A javascript implementation of Tom Schneider's ev, with several modes and upgrades. Allows for real-time, multi-run evolution experiments. With Ev Ware, you can test and limit how much information is imposed on the search by the structure of the program and by particular parameter settings. Discover how likely randomized initializations are to stumble upon targets of your choice. Does ev create information from "scratch" or does it merely reshuffle pre-supplied information? Find out.
A javascript implementation of Tom Schneider's ev, with several modes and upgrades. Allows for real-time, multi-run evolution experiments. With Ev Ware, you can test and limit how much information is imposed on the search by the structure of the program and by particular parameter settings. Discover how likely randomized initializations are to stumble upon targets of your choice. Does ev create information from "scratch" or does it merely reshuffle pre-supplied information? Find out.
Videos
 EvoInfo videos related to evolutionary informatics.
EvoInfo videos related to evolutionary informatics.
Publications
 Peer reviewed papers from conferences and journals.
Peer reviewed papers from conferences and journals.
Donate
 We need your help. Support our ongoing research.
We need your help. Support our ongoing research.